Операции Read и Update: в чём подвох?
Представьте ситуацию: вы пишете приложение и у вас имеется модель данных
В ней содержится много информации, которую хотелось бы скрыть от любопытных глаз, например LastName, Salary, Address или что-то ещё.
Что делать чтобы данные скрыть? Нужно описывать новую DTO-модель (Data Transfer Object), в которой не будет ничего лишнего.
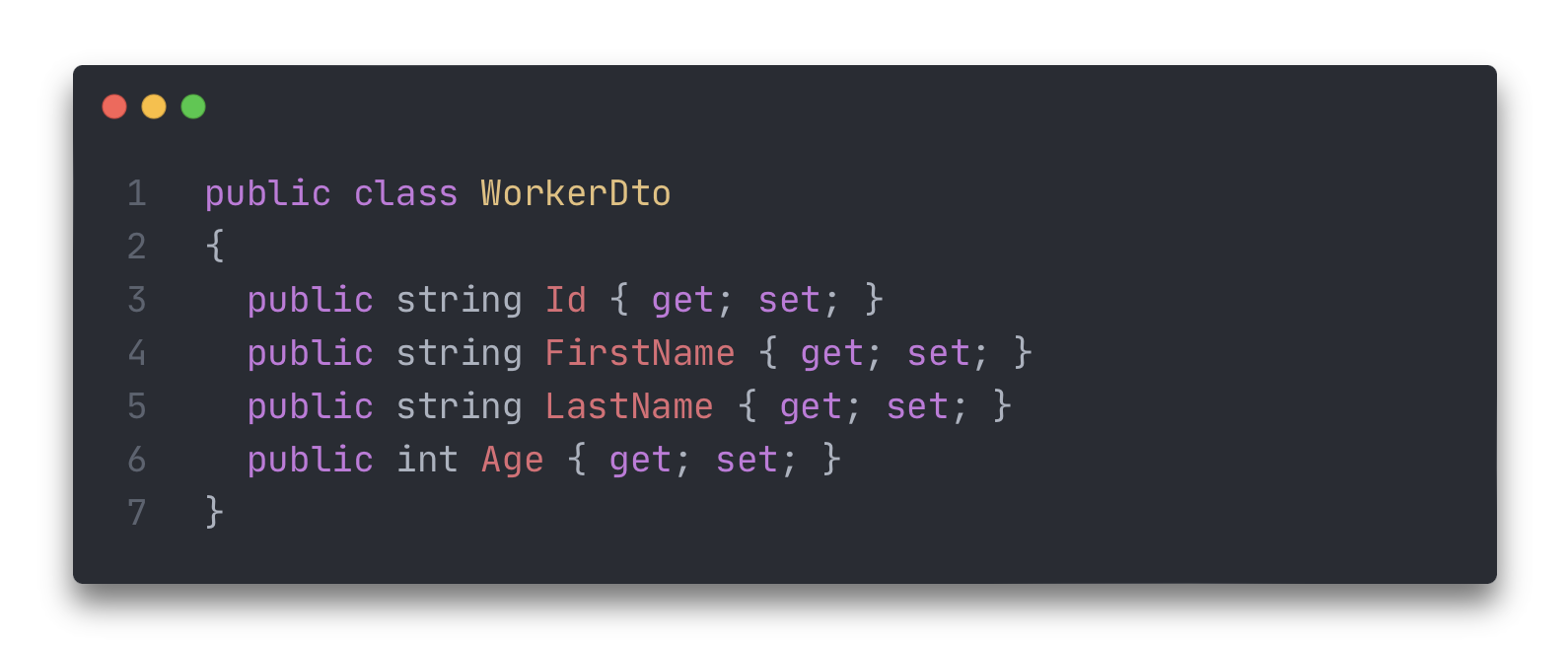
И как следствие нужно писать конвертер, который будет преобразовывать Worker’a в WorkerDto.
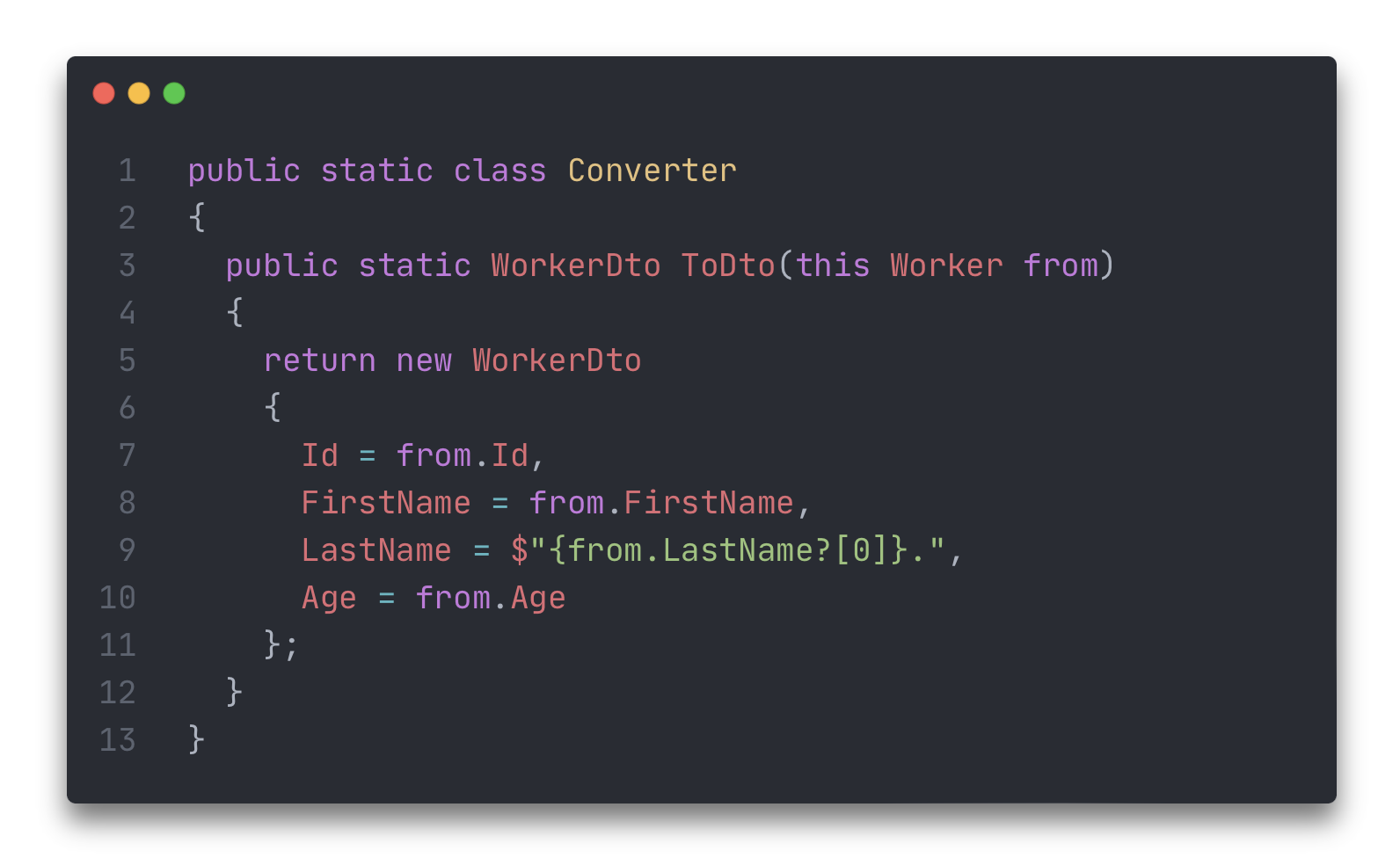
Хорошо. Описали. Какие дальнейшие проблемы возникают при внедрении всего этого в своё приложение?
Первая и очевидная – если в приложении сто моделей, значит нужно писать сто конвертеров. Вторая – если в приложении есть логика изменения данных, то нам придётся писать что-то такое:
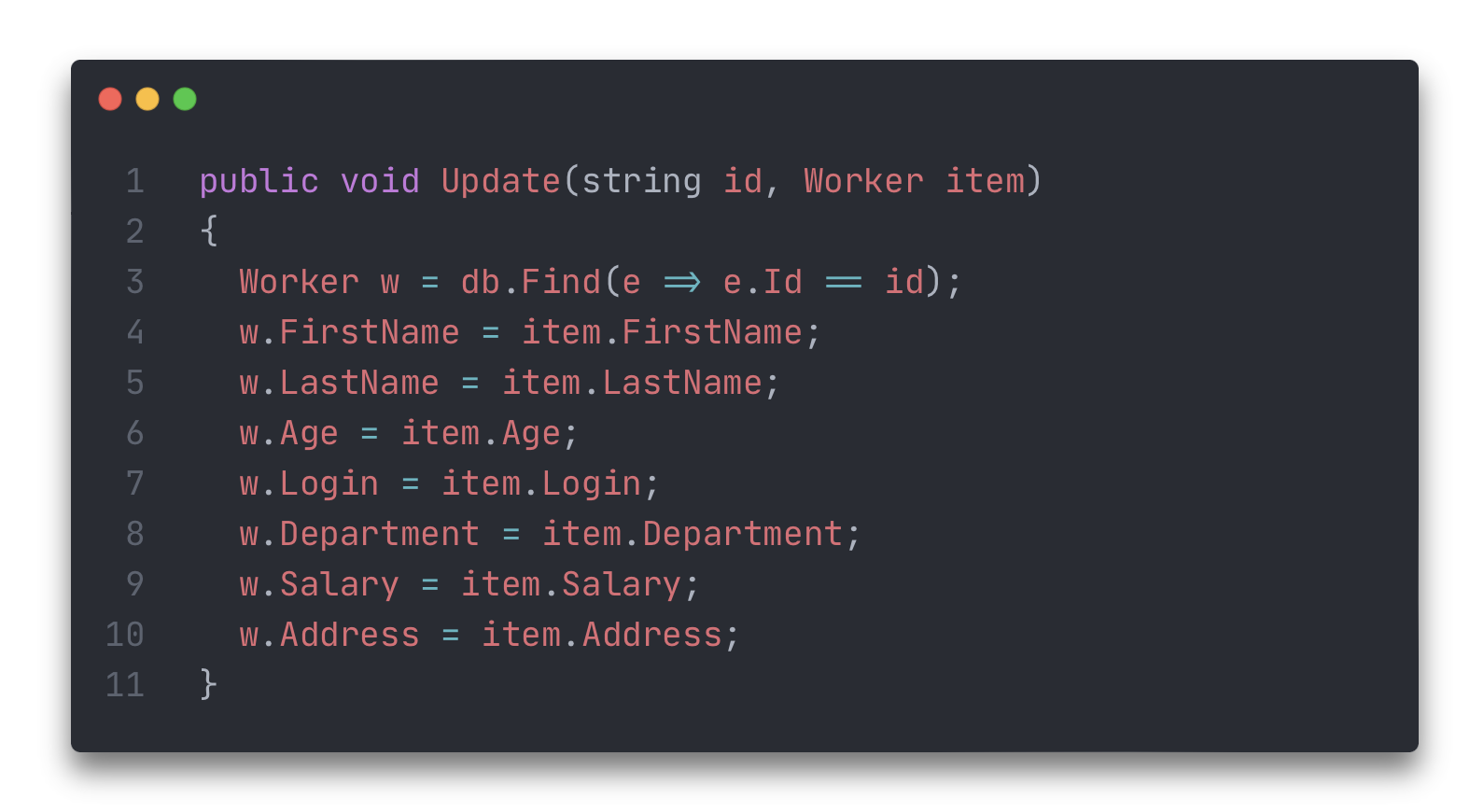
Выглядит ужасно, но это только пол беды, так как тут не стоят проверки на отсутствие данных. Модель может быть гораздо более сложной и тогда нужно проверять наличие данных и если они есть – менять.
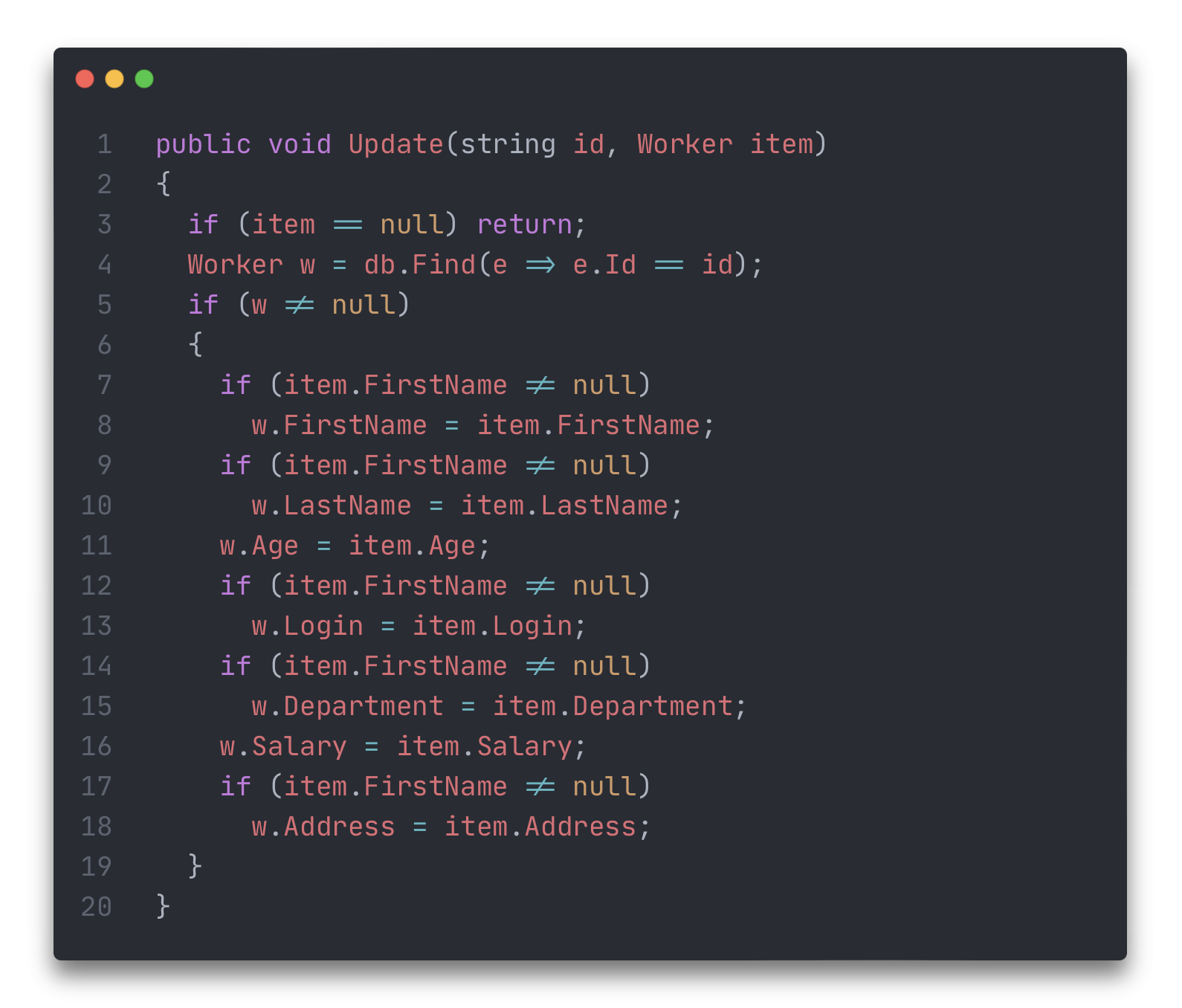
Вспоминаем, что у нас в приложении сотни классов, значит нужно будет делать тысячи if(что-то там ≠ null)... так и выгореть можно, но на радость разработчикам есть библиотеки, выполняющие эту работу за нас – Мапперы.
Установим в свой проект библиотеку
AutoMapper https://automapper.org | https://github.com/AutoMapper
dotnet add package AutoMapperdotnet add package AutoMapper.Extensions.Microsoft.DependencyInjection
Затем нужно сконфигурировать библиотеку. Начать нужно с объекта-наследника Profile для того, чтобы библиотека понимала, что во что нужно "превращать".

"Собрать" экземпляр маппера

и всё готово.
Теперь вместо написания конвертера Листинг 3, достаточно прописать
WorkerDto dto = mapper.Map<WorkerDto>(<worker obj>);
А вместо кода Листинг 5 достаточно этого:
Worker w = db.Find(e => e.Id == id);mapper.Map(<new data>, w);
Согласитесь, это намного ускорит процесс разработки.